原文
Conditional Generative Adversarial Nets
生成对抗网络GAN属于无监督学习,靠博弈逼近概率分布,不需要马尔科夫链,不需要推断,不需要对概率分布进行预先建模。虽然方法简单、粗暴、有效,但这种机制缺乏对生成数据的控制。
条件生成对抗网络CGAN为其加上条件约束后,转化为监督学习,可以有效改善这一问题。将条件变量$y$引入生成器和判别器,使用条件变量指导结果生成。
1 损失函数
$$
\min_G \max_D V(D,G) = \mathbb E_{x \sim p_{data}(x)} [\log D(x|y)] + \mathbb E_{z \sim p_z(z)} [\log (1-D(G(z|y)))]
$$
和GAN相比,D和G的输入加了条件变量$y$。$y$可以是类别标签、其他模态的数据等,非常灵活。
生成器输入是随机噪声$p_z(z)$和条件信息$y$组成的联合隐含表征。
2 网络架构
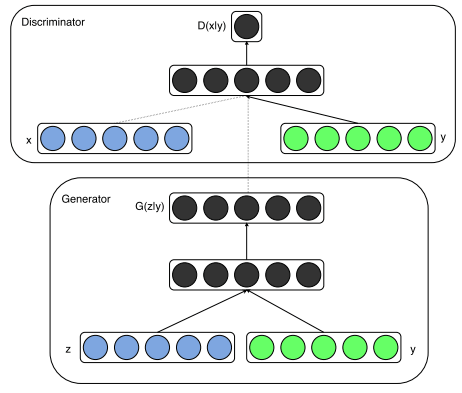
3 实验
3.1 单模态学习
使用0~9数字标签生成MNIST手写图像

3.2 多模态学习
研究图像自动标注问题。
G结构
输入噪声$z$的维度:100 → 500 ReLU
输入图像$y$的维度:使用ImageNet数据集、21000个标签预训练的CNN分类器,将最后一层4096维FC的输出作为图像特征,维度:4096 → 2000 ReLU
输出标签的维度:从YFCC100M数据集训练了200维词向量的skip-gram模型作为输出。
可见$z$和$y$不是一开始就联合了,而是变换了一次维度之后才联合进入200维。
一般来说,多模态联合的方法是直接拼接concat。只要二者都已经被转化成了序列,直接把y拼接在x或z序列后边即可。
D结构
输入词向量$x$的维度:200 → 500 ReLU
输入图像$y$的维度:4096 → 1200 ReLU
然后是1000维最大化输出层联合3个pieces(这部分隐层没看懂,应该也是和G类似,先变换一次维度再联合),最后全部喂给一个sigmoid输出真假。
有的博文中对G的输出和D输入维度产生了疑问,认为不匹配。实际上并没有问题,博文作者搞错了D的输入。我的分析见下:
此处是图像自动标注,因此图像是条件变量$y$。
生成器$G(z|y)$,输入100维噪声 | 4096维图像特征,输出200维词向量;
使用图像$y$及人工标注的标签$x$(即ground truth)训练D,为$D(x|y)$,输入200维人工标注标签的词向量 | 4096维图像特征,输出真;
使用生成的标签让D判断时,输入200维G生成标签的词向量 | 4096维图像特征,输出假。所以我觉得至少从便于理解的角度,此步应该记为$D(G(x|y)|y)$。博文作者首先将D的隐含层的维度当成了输入维度,其次忽略了D在判断G生成数据时还要进行的$y$输入
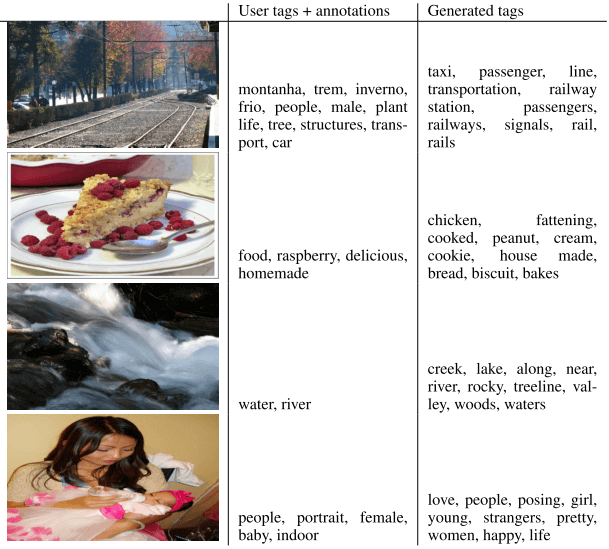
4 展望
文章工作比较初级,更多应用和复杂模型有待研究
文章的图像自动标注只是单标签的,未来可以做多标签
学习语言模型
体会
GAN多模态学习,很有启发。使用条件变量指导模型生成,这一点在设计领域非常有用,设计师或用户给出需求,用这个需求去指导和驱动设计结果的生成。而由于CGAN的灵活性,需求的形式可以是多种多样的。
曾经的多标签分类多麻烦啊,用CGAN进一步去做多标签分类,似乎也很有前景。