原文
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
1 金字塔
高斯金字塔$\mathcal G(I) = [I_0,I_1,…,I_K]$将原始图像$I_0$经过一系列下采样$d(.)$($2\times 2 \to 1$)压缩为$I_K$。
将高斯金字塔的过程反过来,一系列上采样$u(.)$之后可以得到高分辨率的图片。显然正反过程不是完全对称的,因为下采样会丢失信息,而上采样很难还原信息。信息的差构成拉普拉斯金字塔。
拉普拉斯金字塔每层的系数为
$$
h_k = \mathcal L_k(I) = \mathcal G_k(I)-u(\mathcal G_{k+1}(I))=I_k-u(I_{k+1})
$$
所以低分辨率图像可以通过拉普拉斯金字塔递推公式重建为高分辨率图像:
$$
I_k = u(I_{k+1})+h_k
$$
2 生成器
CGAN的损失函数终于在本文中补全了!$D(G(z,c),c)$。好多论文(包括CGAN原文)都没写第二个c,不严谨啊。
生成器是一系列convnet:$\{G_0,…,G_K\}$,这一系列网络做的事情是:
$$
\tilde I_k = u(\tilde I_{k+1})+\tilde h_k = u(\tilde I_{k+1})+G_k(z_k, u(\tilde I_{k+1}))
$$
说人话就是:
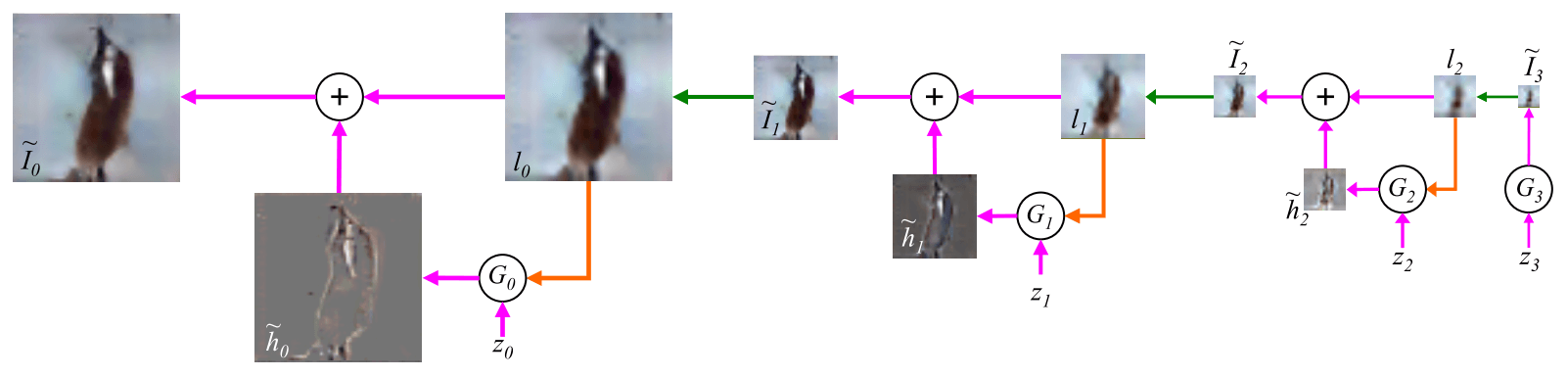
- Step1: 令$\tilde I_{K+1}=0$,则$\tilde I_K = G_K(z_K)$。即$G_K$不是CGAN,其他都是CGAN;
- Step2: 对于CGAN $G_k$,输入噪声$z_k$,条件按照如下方式获得:对$\tilde I_{k+1}$进行上采样得到$l_k$,作为$G_k$的条件输入。$G_k$生成的是拉普拉斯金字塔参数$\tilde h_k = G_k(z_k, u(\tilde I_{k+1}))$;
- Step3: 按照拉普拉斯金字塔递推公式,从上一步中的$l_k$和$\tilde h_k$得到新图像$\tilde I_k$;
- Step4: 重复Step2 ~ 3,直到得到$\tilde I_0$
例如K=3时,生成器架构如下:
3 判别器
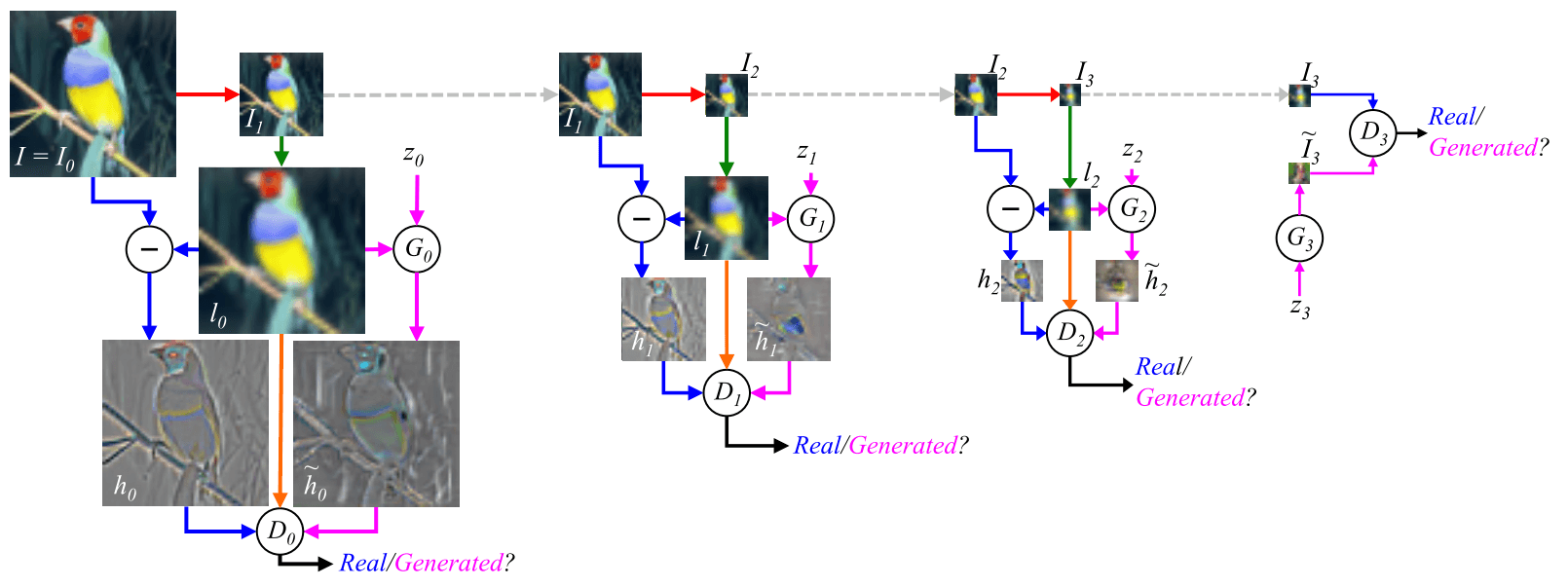
判别器的输入有2种,ground truth是真实的金字塔参数$h_k$,fake是生成的$\tilde h_0$。条件是$l_k$。循环的具体过程是:
- Step1: 输入$I_k$,先下采样为$I_{k+1}$;
- Step2: 将$I_{k+1}$再上采样为$l_k$;
- Step3: 计算拉普拉斯金字塔参数$h_k=I_k-l_k$,作为ground truth输入,$l_k$作为条件输入;
- Step4: 将$z_k,l_k$经$G_k$生成的金字塔参数$\tilde h_k$作为fake输入,$l_k$作为条件输入;
4 实验
以CIFAR10为例(32*32*3图像):
- 噪声是[-1,1]的均匀分布,100维;
- 输入图像是从32*32裁剪出的28*28图像;
- 生成器2层fc带ReLU,每层1200个神经元,然后经过一层fc生成8*8*3的图像;
- 通过金字塔对8*8像素的图像进行上采样,尺寸变化是8,14,28;
- 判别器2层fc,ReLU+Droupout,每层600个神经元,然后一个单元fc的sigmoid输出判断结果;
- SGD学习率0.02,学习率衰减1+4*10^-5每步,初始动量0.5,每步增加0.0008;
在CIFAR10数据集上的结果(CC-LAPGAN是带类别标签的LAPGAN,将标签转化为张量后拼在第一层张量后边):

在LSUN数据集上的结果,第一列是验证集的初始图像,后边是各种结果。

体会
CGAN大法好!
金字塔的每层都是分开训练的,对于堆叠了这么多层的架构来说,降低了训练难度;
分开训练就带来了信息可能会丢失、缺乏全局约束的问题。但是LAPGAN将上一个生成的结果处理下作为下个生成器的条件,堪比残差网络啊,只是没跨那么多;
将CGAN放入拉普拉斯金字塔里,得到了不错的结果。那么是否有其他类似的架构也能将GAN放入呢?更推广一步,除了一些固定的算法架构以外,是否可以有一些更抽象、通用的工作流程可以将GAN放入,从而得到很好的结果呢?比如绘画或雕塑过程、平面设计过程、造房子过程等等……大有可为啊。