原文
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
GAN横空出世,但也存在难训练、易模式崩溃等问题。更别说将CNN和GAN结合起来难度更大。以往的一些尝试都不成功,为此还有了LAPGAN,用了拉普拉斯金字塔来代替CNN采样。
而这篇DCGAN相当经典,倒不是说理论有多么大的创新,而是经历了一系列的尝试,在工程上实现了CNN+GAN深度卷积生成对抗网络,在技术细节上做了很多完善和调整,后续很多做出了很好效果的GAN的变型都是在这篇论文的代码基础上进行的。
其他版本就不研究了,github上有tensorflow版本(包含了CGAN)和tensorlayer版本(没有CGAN)。本文关注CGAN,故对前者进行学习和记录。
文中指出,稳定的DCGAN架构采用了以下手段:
- 卷积代替池化:D用strided conv带步幅的卷积,G用fractional strided conv微步幅卷积
和反卷积很像,都是上采样。虽然论文作者把将微步幅卷积叫做反卷积的行为批判了一番,但是tensorflow版本的代码里用的就是反卷积,没毛病!毕竟CNN里的卷积也没有像数学里的卷积那样转置卷积核啊。
- G,D都使用BN:
- 改善初始化
- 有助于梯度传播
- 防止模式崩溃
- G,D输出层不用BN:
- 直接将BN应用到所有层会导致不稳定
- 移除FC:
- 深度网络最后的FC容易引起过拟合,比较好的办法是用全局平均池化层GAP代替。然而GAP虽然增加了模型的稳定性,但降低了收敛速度
- 折中的方法是G开始输入向量z,(可以被看做FC因为就是个矩阵乘法),然后reshape成4维张量作为卷积栈的开始;D最后一层卷积转化为向量输入到一个sigmoid里
- G输出层tanh,其他层ReLU。
- D所有层LeakyReLU。
文中实际上包含了2套GAN,其中一套是支持输入标签作为条件当CGAN用的。
在学习文章的DCGAN的代码之前,先以MNIST为例实现两个最基础的GAN和DCGAN,二者均是在jupyternotebook上实现的,参考了莫烦和Nelson Zhao的实现。
1 基本层和操作
基本层和操作都在ops.py中。
1.1 LeakyReLU
这个很简单,没什么好说的。
def lrelu(x, leak=0.2, name="lrelu"):
return tf.maximum(x, leak*x)
1.2 卷积,反卷积层
卷积层conv2d由tf.nn.conv2d封装而成,卷积核大小5*5,步长2*2,数量output_dim,padding = same。
def conv2d(input_, output_dim,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="conv2d"):
with tf.variable_scope(name):
# filter :[filter_height, filter_width, in_channels, out_channels]
w = tf.get_variable('w', [k_h, k_w, input_.get_shape()[-1], output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
# input : [batch, in_height, in_width, in_channels]
conv = tf.nn.conv2d(input_, w, strides=[1, d_h, d_w, 1], padding='SAME')
biases = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
conv = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape())
return conv
反卷积层deconv2d由tf.nn.conv2d_transpose封装而成,卷积核大小5*5,步长2*2,数量output_shape[-1],padding = same。
def deconv2d(input_, output_shape,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="deconv2d", with_w=False):
with tf.variable_scope(name):
# filter : [height, width, output_channels, in_channels]
w = tf.get_variable('w', [k_h, k_w, output_shape[-1], input_.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
# input : [batch, in_height, in_width, in_channels]
deconv = tf.nn.conv2d_transpose(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
biases = tf.get_variable('biases', [output_shape[-1]], initializer=tf.constant_initializer(0.0))
deconv = tf.reshape(tf.nn.bias_add(deconv, biases), deconv.get_shape())
if with_w:
return deconv, w, biases
else:
return deconv
1.3 全连接层
前面说到,D的最后一层要把前边的卷积结果转化为一个序列,喂进sigmoid里。该层可以被看做是fc层。其定义如下:
def linear(input_, output_size, scope=None, stddev=0.02, bias_start=0.0, with_w=False):
shape = input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
try:
matrix = tf.get_variable("Matrix", [shape[1], output_size], tf.float32,
tf.random_normal_initializer(stddev=stddev))
except ValueError as err:
msg = "NOTE: Usually, this is due to an issue with the image dimensions. Did you correctly set '--crop' or '--input_height' or '--output_height'?"
err.args = err.args + (msg,)
raise
bias = tf.get_variable("bias", [output_size],
initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_, matrix) + bias, matrix, bias
else:
return tf.matmul(input_, matrix) + bias
显然在D中,linear的传入参数output_size = 1,才能将4维张量转化为1维序列输入输入sigmoid;而在G中,linear的使用和D是对称的——将z转化为4维张量作为反卷积栈的开始。
2 DCGAN基本参数
DCGAN模型的代码在model.py中。
class DCGAN(object):
def __init__(self,
sess,
input_height=108,
input_width=108,
crop=True,
batch_size=64,
sample_num = 64,
output_height=64,
output_width=64,
y_dim=None, # 条件y的维度
z_dim=100,
gf_dim=64, # G中第一层conv的卷积核数量
df_dim=64, # D中第一层conv的卷积核数量
gfc_dim=1024, # G中fc的神经元数量
dfc_dim=1024, # D中fc的神经元数量
c_dim=3, # 色彩维度,灰度图为1
dataset_name='default',
input_fname_pattern='*.jpg',
checkpoint_dir=None,
sample_dir=None,
data_dir='./data'
):
3 判别器
源码接受MNIST,CelebA和LSUN三个数据集,其中对于MNIST而言,标签被作为条件输入。所以实际上支持了GAN和CGAN。
def discriminator(self, image, y=None, reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
# GAN
if not self.y_dim:
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [self.batch_size, -1]), 1, 'd_h4_lin')
return tf.nn.sigmoid(h4), h4
# CGAN
else:
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
x = conv_cond_concat(image, yb)
h0 = lrelu(conv2d(x, self.c_dim + self.y_dim, name='d_h0_conv'))
h0 = conv_cond_concat(h0, yb)
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim + self.y_dim, name='d_h1_conv')))
h1 = tf.reshape(h1, [self.batch_size, -1])
h1 = concat([h1, y], 1)
h2 = lrelu(self.d_bn2(linear(h1, self.dfc_dim, 'd_h2_lin')))
h2 = concat([h2, y], 1)
h3 = linear(h2, 1, 'd_h3_lin')
return tf.nn.sigmoid(h3), h3
GAN的支持是比较简单的,4层常规的卷积+一层fc后输入到sigmoid;CGAN比较值得深入学习:对于MNIST而言,D设置了2个卷积层+1个fc+1个sigmoid。输入的image维度是[64, 28, 28, 1],还有标签y,维度y_dim=10,在卷积中被reshape成yb,维度[64,1,1,10]。image和yb拼接的方法见ops.py:
def conv_cond_concat(x, y):
"""Concatenate conditioning vector on feature map axis."""
x_shapes = x.get_shape()
y_shapes = y.get_shape()
return concat([
x, y*tf.ones([x_shapes[0], x_shapes[1], x_shapes[2], y_shapes[3]])], 3)
concat就是tf.concat,可见是先将yb的前3维以1为值扩展为和image前三维相同维度,然后和image在最后一维上进行拼接。所以最后得到的D中的x维度是[64,28,28,11]。
于是后续的卷积过程为:
$$
\begin{aligned}
x &[64,28,28,11] \to (conv(x,11), lrelu, concat(yb)) \to \\
h0 &[64,14,14,11+10] \to (conv(h0,64+10),bn,lrelu,reshape([64,-1]), concat(y)) \to \\
h1 &[64,7\times7\times74+10] \to (conv(h1,1024),bn,lrelu,concat(y)) \to \\
h2 &[64,1024+10] \to (fc) \to \\
h3 &[64,1] \to (sigmoid)
\end{aligned}
$$
不看不知道,原来CGAN在每个卷积层都要拼接条件,而不是开始拼完就一劳永逸的。在reshape之前,拼接的是yb;reshape之后,拼接的是y——为什么每层都要concat?
4 生成器
同D,G也支持了CGAN。配合文中给出的图食用
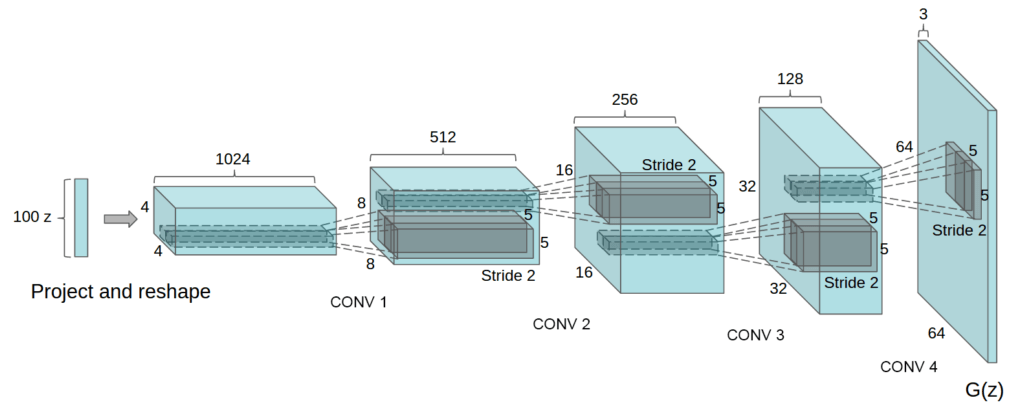
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
# GAN
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = deconv2d(
h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = deconv2d(
h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = deconv2d(
h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
# CGAN
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.expand_dims(tf.expand_dims(y, 1),2)
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(
self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin')))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin')))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(deconv2d(h1,
[self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2')))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(
deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
z是100维噪声。yb和D中一样是[64,1,1,10]维张量。z和y拼接后变为[64,1,1,110]维。G和D对称但是多了一层fc:2层fc+2层deconv。CGAN的反卷积过程为:
$$
\begin{aligned}
z &[64,1,1,110] \to (fc,bn,relu,concat(y)) \to \\
h0 &[64,1024+10] \to (fc,bn,relu, concat(y)) \to \\
h1 &[64,7,7,128+10] \to (deconv, relu, reshape(64,14,14,128),concat(yb)) \to \\
h2 &[64,14,14,128+10] \to (deconv, relu) \to \\
h3 &[64,28,28,3] \to (sigmoid)
\end{aligned}
$$
5 训练过程
5.1 实例化
self.G = self.generator(self.z, self.y)
self.D, self.D_logits = self.discriminator(inputs, self.y, reuse=False)
self.sampler = self.sampler(self.z, self.y)
self.D_, self.D_logits_ = self.discriminator(self.G, self.y, reuse=True)
损失
def sigmoid_cross_entropy_with_logits(x, y):
try:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
except:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, targets=y)
self.d_loss_real = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
5.2 优化
和GAN原文不同,采用Adam优化器,学习率$\alpha = 0.0002$,动量系数$\beta _1 = 0.5$
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
5.3 更新
和原文不同,为了防止D收敛比G快太多,D更新一次,G更新两次。
for epoch in xrange(config.epoch):
if config.dataset == 'mnist':
batch_idxs = min(len(self.data_X), config.train_size) // config.batch_size
else:
self.data = glob(os.path.join(
config.data_dir, config.dataset, self.input_fname_pattern))
np.random.shuffle(self.data)
batch_idxs = min(len(self.data), config.train_size) // config.batch_size
for idx in xrange(0, int(batch_idxs)):
if config.dataset == 'mnist':
batch_images = self.data_X[idx*config.batch_size:(idx+1)*config.batch_size]
batch_labels = self.data_y[idx*config.batch_size:(idx+1)*config.batch_size]
else:
batch_files = self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch = [
get_image(batch_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for batch_file in batch_files]
if self.grayscale:
batch_images = np.array(batch).astype(np.float32)[:, :, :, None]
else:
batch_images = np.array(batch).astype(np.float32)
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \
.astype(np.float32)
if config.dataset == 'mnist':
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={
self.inputs: batch_images,
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z, self.y:batch_labels })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({
self.z: batch_z,
self.y:batch_labels
})
errD_real = self.d_loss_real.eval({
self.inputs: batch_images,
self.y:batch_labels
})
errG = self.g_loss.eval({
self.z: batch_z,
self.y: batch_labels
})
else:
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.inputs: batch_images, self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({ self.inputs: batch_images })
errG = self.g_loss.eval({self.z: batch_z})
counter += 1
print("Epoch: [%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (epoch, config.epoch, idx, batch_idxs,
time.time() - start_time, errD_fake+errD_real, errG))
if np.mod(counter, 100) == 1:
if config.dataset == 'mnist':
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
self.y:sample_labels,
}
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
else:
try:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
except:
print("one pic error!...")
if np.mod(counter, 500) == 2:
self.save(config.checkpoint_dir, counter)
5.4 结果采样
在训练过程中,对结果进行采样和显示,实际上就是生成器采样。不过这里不是直接调用G生成结果,而是写了一个和G共享参数、架构相同的sampler来进行采样。为什么这样做呢?好像是纯粹为了summary的分离。
6 实验
在数据下载阶段就遇到了bug,download.py会逐个下载解压4个mnist的gz文件,但死活没法解压gz,路径是正常的,转义符\\和/都不行。只能先跳过这一步,用以前下载的mnist。
有时候会报错OSError: raw write() returned invalid length xxx (should have been between 0 and yyy),这时候需要加上
import win_unicode_console
win_unicode_console.enable()
在DCGAN的初始化函数里,会有个判断self.data的长度是否比batch-size小的逻辑,但是在用mnist测试时,self.data是没有的,所以直接跑就会报错。应该把这句放到判断数据集的条件分支中,要么就注释或者try掉。(看代码其他部分各种if或try以兼容三类数据集和tf版本,还是很严谨的,怎么这里就忽略了呢……)
前面提到CGAN每层都拼接条件的到底有什么作用,这里做了几个实验对比下:
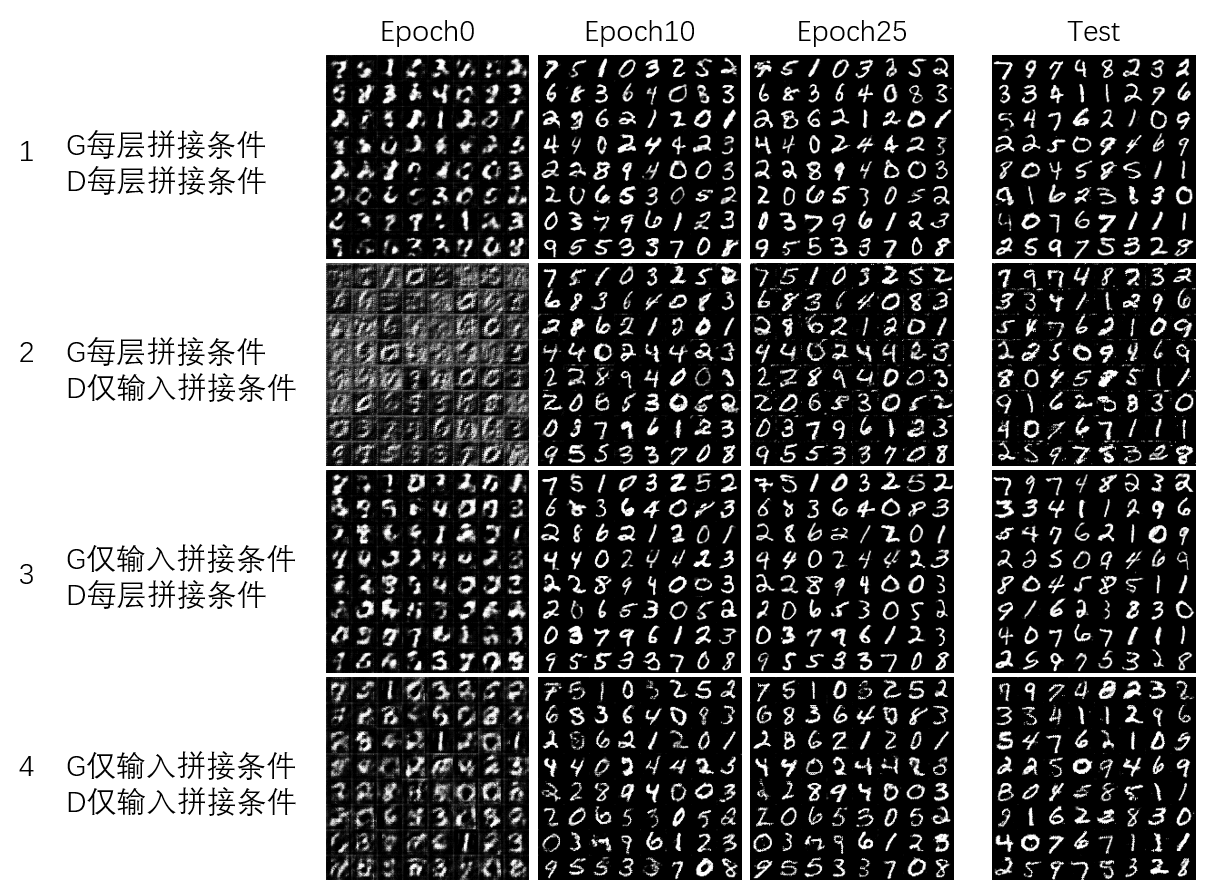
可见和原始的1相比,2在图像边缘有较多噪声;3在文字边缘有少许噪声;4在文字笔画内有较多噪声(有点像棋盘效应的效果),背景有少许噪声。各实验的训练速度和最终收敛情况看不出太大差别。结合非条件DCGAN的结果,给出以下猜想,没大量实验过,不一定对:
- 只是在输入层拼接条件,会引入噪声
- G每层拼接条件就有助于消除前景噪声
- D每层拼接条件有助于消除背景噪声
前文说过,基于Tensorlayer实现的DCGAN没有CGAN,我在它基础上实现了一个CGAN的版本。不得不说Tensorflow版的DCGAN真的写的很好,模块性做的很赞。Tensorlayer实现起来并没有减少多少代码,而且感觉训练部分的代码稍微有些凌乱。