原文
Image-to-image translation with conditional adversarial networks
代码
https://github.com/phillipi/pix2pix
灰度图、线描图、彩图……图像有很多类型,将图像在多种类型之间转化,实际上可以理解为图像到图像的“翻译”——这就就是基于CGAN的pix2pix做的事情。以往每一种“翻译”都是一个独立的问题,需要用独特的方法解决。但pix2pix给出了处理这类问题的统一框架。
以往使用CNN解决此类问题时,需要专家知识——精心设计损失函数,不然效果会很差。对于使用者来说,不需要像以往那样调整各种复杂的参数才能达到最终效果;对于开发者来说,则不需要手动设计复杂的损失函数,模型自己会去学习。
虽然用的是已有的一些技术,但这篇文章仍然有较大贡献:
- 阐述了CGAN在此类问题上的通用性,而非像以往研究那样局限在某个具体问题上;
- 提供了实现良好效果的简单框架。
1 损失函数
pix2pix框架也是博弈问题:
$$
\arg \min_G \max_D \mathcal L_{\rm cGAN}(G,D) + \lambda \mathcal L_{L1}(G)
$$
其中包含了一个L1正则化项(见后文解释)和CGAN的损失函数:
$$
\mathcal L_{\rm cGAN}(G,D) = \mathbb E_{x,y}[\log D(x,y)] + \mathbb E_{x,z}[\log(1-D(x,G(x,z))]
$$
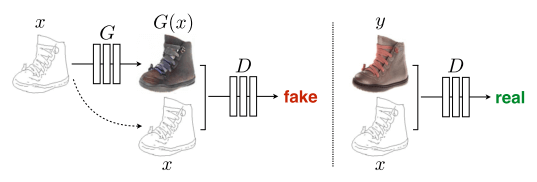
其中$x$是输入图像(即条件),$y$是ground truth,$z$是随机噪声。
我觉得这个损失函数写的比CGAN最初的那篇论文里好多了。最初的论文里,使用$y$作为条件,$x$作为ground truth,但D判断生成数据时的项是$D(G(z|y))$,显然遗漏了条件,应该用$D(G(z|y)|y)$更恰当
2 生成器G
生成器G需要做两件事:
- 骗过判别器D(显然,在这里“骗过”指$x$到G生成的结果$G(x,z)$之间的映射看起来像$x$到$y$之间的映射)
- 生成的图像尽可能真实,这里使用L1增强真实性。L1损失常常会导致生成的图像模糊。GAN则会导致生成的图像有一些高频噪声。这二者一结合,就把高频特征和低频特征都给抓住了,不至于太模糊,又消除了噪声。所以才有了1中的正则化项:
$$
\mathcal L_{L1}(G) = \mathbb E_{x,y,z}[||y-G(x,z)||_1]
$$
CGAN最初用的是高斯噪声,但这里实践发现没有效果,因此使用的是dropout噪声。模型输出结果的随机性很小。论文也指出,如何设计出随机性更大的CGAN,仍然是个有待研究的问题。
以往的神经网络架采用编码器-解码器架构,所有信息都是逐层传递的。但输入输出其实应该信息共享,比如边角轮廓等。这里采用了U-Net架构,将编码器部分层的信息绕过最窄的编码层,直接传递到解码器的部分层。具体来说,将第i层拼接到第n-i层:

判别器D
前面说过,L1损失捕捉到了低频特征,即避免了全局变形。为了更好地捕捉高频特征,保证局部精准,这里提出了PatchGAN的架构,将图像分成N*N区域,分别判断每个区域的真实性,再平均输出。
训练
- 和GAN一样交替训练D,G;
- minibatch梯度下降,使用Adam优化器,学习率0.0002,momentum参数$\beta_1=0.5, \beta_2=0.999$;
- 推断阶段,G运行的方法和训练阶段相同,也进行dropout;而且batch normalization使用的是测试batch,而不是训练batch;
- batch normalization根据具体问题在1-10之间选择。当选择1的时候,术语叫做instance normalization。
实验
文章进行了广泛的试验:
- 语义分割标签 $\leftrightarrow$ 照片
- 建筑标签 $\leftrightarrow$ 照片
- 地图 $\leftrightarrow$ 航拍图
- 黑白 $\leftrightarrow$ 彩色
- 轮廓图 $\leftrightarrow$ 照片
- 草图 $\leftrightarrow$ 照片
- 白天 $\leftrightarrow$ 黑夜
- 热感图 $\leftrightarrow$ 彩图
- 残缺图片 $\leftrightarrow$ 补全图片
可见pix2pix的确是一个通用性非常强的框架。
小数据集就可以生成很好的结果,白天黑夜互转的数据集甚至还不到100个。计算速度也很快。
结果评价采用了2种方式:
- AMT人工评价真假;
- 输入到已有的图像识别系统中看能不能识别出其中的物体,如FCN
文章还对L1损失和CGAN损失的组合在语义分割标签和建筑标签转化为照片的试验中进行了测试:

L1模糊,CGAN噪声,L1+CGAN效果很好。
U-Net的效果

不用U-Net时,明显get不到高层特征,L1+CGAN出现了奇怪的细节;用了U-Net之后就好多了。
PatchGAN的patch大小测试

patch太小,细节不够明显;patch太大,细节基本上没有进一步改善,但色彩会削弱。
其他人使用pix2pix框架开发的内容

体会
- L1损失抓全局,PatchGAN抓局部,合适的大小才能有好结果,不用精细到像素;
- U-Net保留高层语义特征
- 虽然大都是已有模型的组合,但稍微的改进、强调达到通用的效果,配上丰富的试验和充分的评价,就有研究价值和创新性