原文
Generative Adversarial Text to Image Synthesis
图像自动标注乃至自动起标题的研究非常火热,MSCOCO还举办过几次比赛。但反过来,文本生成图像的研究上,谷歌DRAW等基于RNN的模型有了不错的效果,本文则使用最火的生成对抗网络来实现。
1 损失函数
$$
\min_G \max_D V(D,G) = \mathbb E_{x \sim p_{data}(x)}[\log D(x,\varphi(t))] + \mathbb E_{z \sim p_z(z)}[\log D(G(z,\varphi(t)),\varphi(t)]
$$
z为随机噪声,$\varphi$为句子的编码器,将文本序列t编码为嵌入$\varphi(t)$,然后拼接到z上。
实际上就是增强版的CGAN啊,条件就是$\varphi(t)$
2 架构
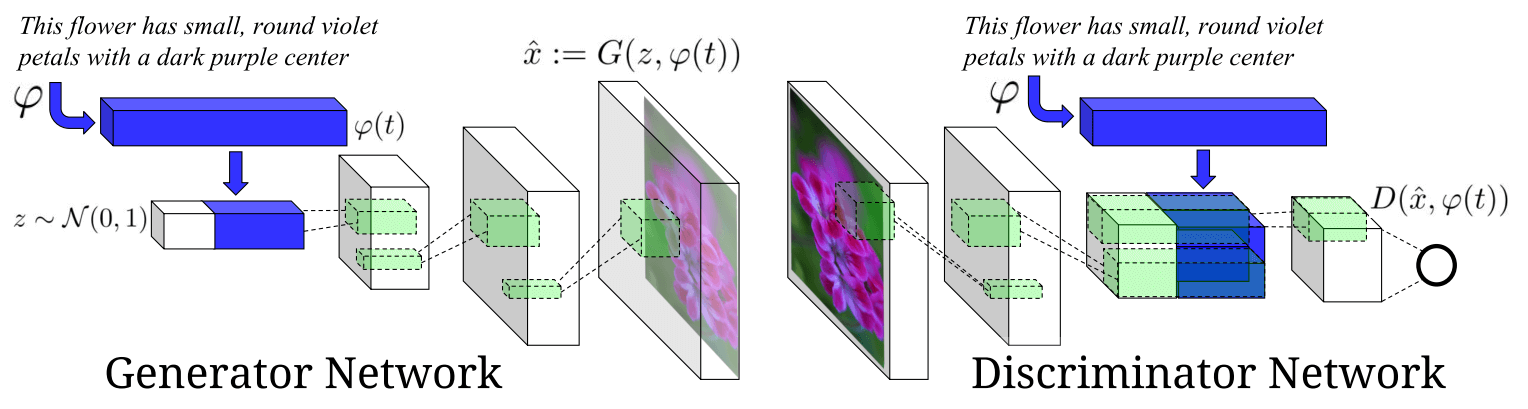
2.1 条件匹配判别器GAN-CLS
输入真实图像时,输入的文字描述可能是正确也可能是错误,因此判别器需要把 { 真实图像,错误描述 } 也作为不接受的结果,强化D的训练效果。
算法
for n=1 to S do
$h \gets \varphi(t)$ 编码正确描述
$\hat h \gets \varphi(\hat t)$ 编码错误描述
$z \sim \gets N(0,1)^Z$ 随机噪声
$\hat x \gets G(z,h)$ 生成器生成图像
$s_r \gets D(x,h)$ 真图像,正确描述
$s_w \gets D(x,\hat h)$ 真图像,错误配描述
$s_f \gets D(\hat x, h)$ 假图像,正确描述
$\mathcal L_D \gets \log(s_r)+(\log(1-s_w)+\log(1-s_f))/2$
$D \gets D-\alpha \partial \mathcal L_D / \partial D$ 更新判别器
$\mathcal L_G \gets \log(s_f)$
$G \gets G - \alpha \partial \mathcal L_G / \partial G$ 更新生成器
2.2 流形插值学习GAN-INT
对句子的嵌入进行插值,可以得到渐变的生成结果。给定2个描述$t_1,t_2$,内插值权重为$\beta$,向生成器引入最小化项:
$$
\mathbb E_{t_1,t_2 \sim p_{data}}[\log(1-D(G(z,\beta t_1 + (1-\beta)t_2)))]
$$
生成器可以填补数据流形上的空缺。需要注意的是,插值出的语料并没有对应的真实图像。
这一点很有意思。其实用有真实图像的文本训练很有可能会导致结果在尽量模仿真实图像,这样会使结果缺乏多样性。但将没有真实图像的文本作为输入,就不存在“模仿真实”这一说了,“创意”也就随之而生。
2.3 风格转移
这里的风格转移,驱动是风格化的图片,目标是文本。因此需要反转G来构造一个风格编码器S,将生成的图片$\hat x$编码为噪声z。风格编码器S的损失为
$$
\mathcal L_{style} = \mathbb E_{t,z \sim \mathcal N(0,1)}||z-S(G(z,\varphi(t)))||^2_2
$$
则将驱动图片x向文本t进行风格转移的过程如下:
- $s \gets S(x)$ 将驱动图片x使用风格编码器S转化为风格噪声s
- $\hat x \gets G(s,\varphi(t))$ 然后和目标文本一起输入生成器G,生成风格转移的结果$\hat x$
这部分我觉得很有意思!
3 实验
原文代码是基于torch的DCGAN编写的,这里有tensorlayer的作者使用tensorflow+tensorlayer实现的版本,用了残差块。
文本生成图像结果

风格转移结果

插值结果

体会
这篇文章倒不如说是对CGAN的详细实现。GAN-CLS-INT的设计,CLS提升了判别器的训练效果,INT提供了生成更丰富结果的方法。从生成的图片上来说,除了INT的插值,其他结果仍然是“依葫芦画瓢”。
让我觉得有意思的,反而是风格转移那里。不过用噪声编码风格、用风格图片驱动文本生成图片结果,这个方向其实和以前的neural style transfer的套路差不多,只是多了个文本生成图像。
如果反过来,用文本作为驱动,来改变输入图像,生成风格化的结果,这个角度就比较有趣了——而且应用场景也很明确:买家找到一个商品,但想要另一种风格的同类商品。和驱动图片相比,驱动文本可能是普通买家容易提供的。关于这点暂且不表,在以后的文章中再深入探究。