原文
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
StackGAN是两个堆叠的CGAN,分别生成低、高精度的图像。
1 结构
- 第一阶段:从文本描述和随机噪声生成基本形状和色彩、背景的低分辨率图像;
- 第二阶段:从文本描述进一步强化第一阶段的结果,提高分辨率,改善图像细节。
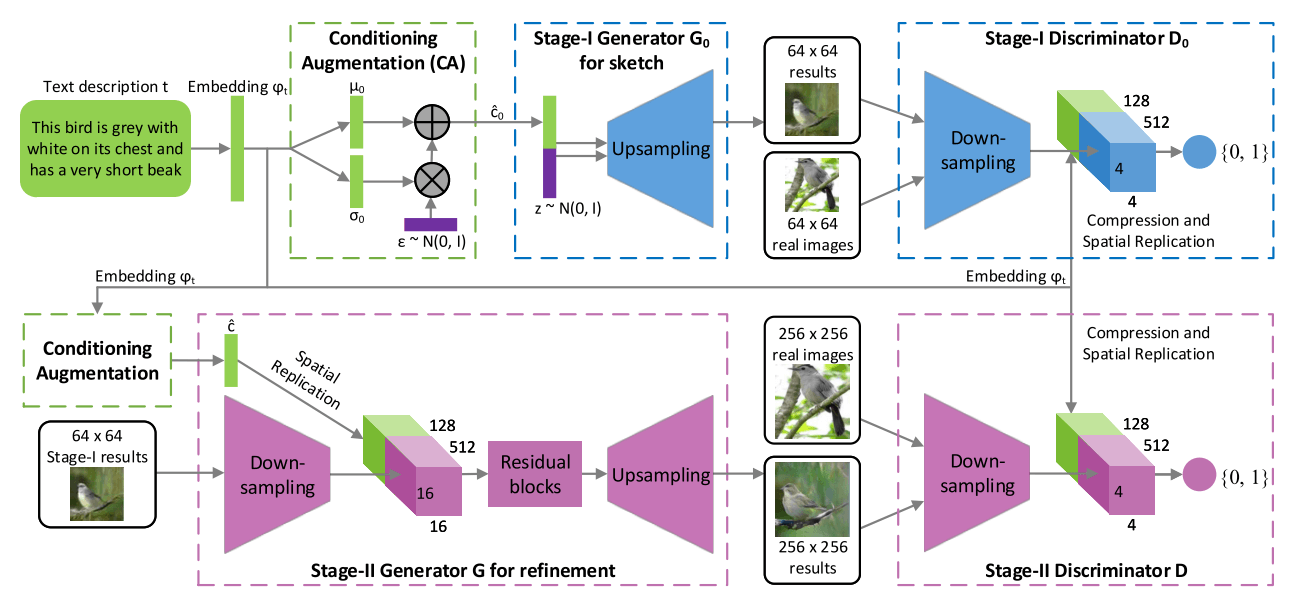
2 条件增强CA
在文本到图像中,文本嵌入的隐空间维度通常在100维以上。数据有限时,流形就会不连续,对学习不利。以往是一个文本嵌入$\varphi_t$作为条件c,对应一个图像;为了缓解这个问题,进行如下处理:
- 求文本嵌入的独立高斯分布$\mathcal N(\mu (\varphi _t), \sum(\varphi_t))$;
- 从分布中随机采样,得到多个条件变量$\hat c$;
- 多个条件变量可以对应一个图像
上述方法扩充了文本-图像对的数量,由以前的一个文本嵌入对应一个图像变成了多个文本嵌入分布的采样对应一个图像。通过随机采样在一定程度上填补了流形的孔洞,鲁棒性更强。
为了进一步增强光滑性,并避免过拟合,再加入正则化项:
$$
D_{KL}(\mathcal N(\mu (\varphi _t), \sum(\varphi_t)||\mathcal N(0,I))
$$
这个正则化是文本嵌入的高斯分布和标准高斯分布的KL散度(相对熵)。
文中提到,条件增强过程中引入的随机性对文本-图像的转化很有帮助,因为相同的句子通常对应多种结果(一千个读者一千个哈姆雷特)。这个很有意思,它实际上是如下过程:单个文本 – 附近采样得到的多个文本(可以理解为相似表述) – 图像。虽然在增强出来的样本中是一图对多句($\hat c \sim x$),但训练出来的模型就可以达到一句对多图($c \sim \hat x$)的效果了。
3 第一阶段
3.1 损失函数
判别器$D_0$损失
$$
\mathcal L_{D_0} = \mathbb E_{(I_0,t)\sim p_{data}}[\log D_0(I_0,\varphi _t)] + \mathbb E_{z\sim p_z, t\sim p_{data}}[\log(1-D_0(G_0(z,\hat c_0),\varphi_t))]
$$
$I_0$是真实图像
生成器$G_0$损失
$$
\mathcal L_{G_0} = \mathbb E_{z\sim p_z, t\sim p_{data}}[\log(1-D_0(G_0(z,\hat c_0),\varphi_t))]+\lambda D_{KL}(\mathcal N(\mu _0(\varphi_t),\sum_0(\varphi_t))||\mathcal N(0,I))
$$
超参数$\lambda=1$
3.2 生成器架构
- 文本嵌入$\varphi_t$先经过一层fc生成$\mu_0$和$\sigma_0$,将$\sigma_0$作为对角元素,从而构造高斯分布$\mathcal N(\mu (\varphi _t), \sum(\varphi_t))$;
- 对高斯分布随机采样得到$N_g$维的条件向量$\hat c_0$。计算方法为$\hat c_0 = \mu_0 + \sigma_0 \bigodot \epsilon$。其中$\bigodot$是元素乘,$\epsilon \sim \mathcal N(0,I)$;
- $\hat c_0$和$N_z$维的噪声拼接,经过多次上采样生成图像。
3.3 判别器架构
- 文本嵌入$\varphi_t$先通过一层fc压缩成$N_d$维向量,然后复制成$M_d \times M_d \times N_d$维的张量;
- 图像经过一系列下采样变成宽高为$M_d \times M_d$维的张量,然后和上述文本转化成的张量在深度上拼接;
- 经过1层1*1的卷积和1层单节点的fc输出判断。
4 第二阶段
第一阶段生成的低分辨率结果往往会丢失一些细节,并且会出现扭曲。
4.1 损失函数
判别器D损失
$$
\mathcal L_D = \mathbb E_{(I,t)\sim p_{data}}[\log D(I,\varphi _t)] + \mathbb E_{s_0 \sim p_{G_0}, t\sim p_{data}}[\log(1-D(G(s_0,\hat c),\varphi_t))]
$$
其中,$s_0 = G_0(z,\hat c_0)$是第一阶段生成的图像。
生成器G损失
$$
\mathcal L_G = \mathbb E_{s_0 \sim p_{G_0}, t\sim p_{data}}[\log(1-D(G(s_0,\hat c),\varphi_t))]+\lambda D_{KL}(\mathcal N(\mu (\varphi_t),\sum(\varphi_t))||\mathcal N(0,I))
$$
文本嵌入和第一阶段共享,但是采用的条件增强fc层不和第一阶段共享。
4.2 生成器架构
生成器是带残差块的编码-解码器网络。
- 文本嵌入$\varphi _t$转化为$N_g$维的$\hat c$,然后复制扩充为$M_g \times M_g \times N_g$维的张量;
- 第一阶段生成的$s_0$经过一系列下采样块(即编码器),转化为宽高为$M_g \times M_g$维的张量,然后和上述文本转化成的张量在深度上拼接;
- 拼接后的张量经过一系列残差块(即解码器),生成高分辨率的图像。
4.3 判别器架构
类似第一阶段,只是因为输入图像分辨率更高,下采样更多。
5 网络细节
上采样块:3*3 stride单卷积,除最后一层,每层BN+ReLU。
残差块:3*3 stride单卷积,BN+ReLU。
下采样块:4*4 stride2卷积,BN+LeakyReLU,第一层没有BN。
$N_g=128, N_z = 100, M_g = 16, M_d = 4, N_d = 128, W_0 = H_0 = 64, W = H = 256$
一阶段训练600次,二阶段训练600次,ADAM解算器,动态学习率,初始为0.0002,每100次降为之前的1/2。
6 实验结果
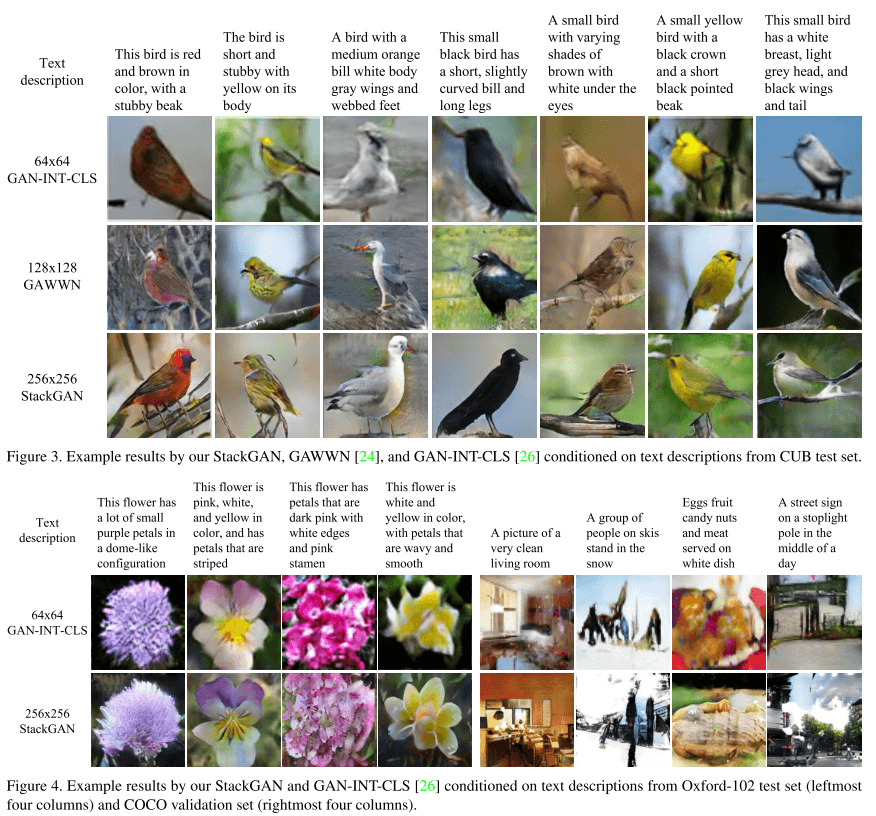
在不同数据集上和不同网络架构相比的结果:
分阶段的结果:

有无CA对比:

插值结果:

源码是用python 2.7和比较低版本的tensorflow写的,有待升级啊~
体会
这篇文章让人想起LAPGAN(文章当然也提到了这篇经典论文)。两个堆叠的CGAN比LAPGAN的架构要简单了很多,而且应用场景是文本到图像。
LAPGAN、GAN-CLS-INT和StackGAN显示,先粗后精的生成思路确实达到了不错的效果,这种思路或许是接下来图像生成研究的热门方向。
就像在LAPGAN文献阅读的体会中谈到的,将GAN用到一些流程中组成的复杂架构,将朴素的“从粗到精”推广到工作序列,能够提升结果质量、丰富应用场景、加快落地。