原文
Be Your Own Prada: Fashion Synthesis with Structural Coherence
根据文本对人物换装。首先对照片进行语义分割,作为隐含的空间排布约束。然后将语义分割的结果作为条件,使用CGAN生成最终换装结果。论文提出的方法保证了结构一致性:
- 身体形状和姿态
- 根据文本描述生成区域及对应的纹理
- 增强身体各部分在视觉上的连贯性
1 概述
数据处理:原始图像$I_0$,语义分割映射$S_0$包括头发、脸、上衣、裤子等等区域和形状。
把输入图像的空间配置作为条件来生成目标。
保留信息
2值编码的向量a来抽取着装者的详细信息,如性别、长短发、是否戴眼镜、是否带帽子等等,还有肤色的RGB均值、宽高比等等。a中所包含的信息是最后结果中需要保留的。
设文本编码为d,设计编码定义为d=(a,v)。给定设计编码d和语义分割$S_0$,目标是生成图像$\tilde I$,符合v保留a。当然在训练过程中,$\tilde I = I_0$
过程
整个过程可以概括为2个阶段:
- 人体分割形状生成 $\tilde S \gets G_{\rm shape}(z_S,\downarrow m(S_0),d)$
- 纹理渲染 $\tilde I \gets G_{\rm image}(z_I,\tilde S d)$
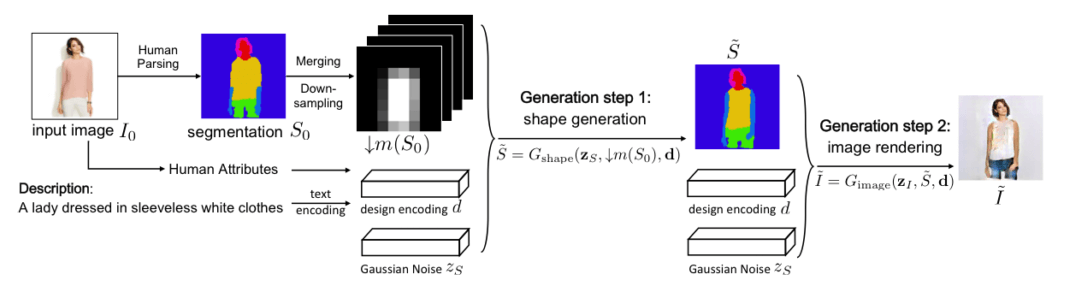
空间约束:第一阶段中,$\downarrow m(S_0)$是原始语义分割$S_0$的低分辨率表示,作为空间约束,来保证生成的分割形状$\tilde S$保留原图的形状和姿态。
组合映射:在第二个阶段中,每个分割部分都是独立生成的,然后组合到一起呈现出最终的结果。
2 分割映射生成$G_{\rm shape}$
$$\tilde S \gets G_{\rm shape}(z_S,\downarrow m(S_0),d)$$
以空间约束$\downarrow m(S_0)$为条件,生成语义分割映射$\tilde S$。高斯噪声$z_S \in \mathbb R^{100}$,初始图像$I_0 \in \mathbb R^{m \times n \times 3}$。
初始的语义分割映射$S_0$是像素级的独热编码$S_0 \in \{0,1\}^{m \times n \times L}$,L是标签的数量,文中取7:背景、头发、脸、上衣、裤子、腿、胳膊。
2.1 空间约束
空间约束$\downarrow m(S_0) \in [0,1]^{m^\prime \times n^\prime \times L^\prime}$由$S_0$下采样得到。这里的类别缩减了,$L^\prime=4$:背景、头发、脸、其他。
为什么要这个粗略的空间约束呢?因为$S_0$和d可能冲突,比如$S_0$是短裤,d中的描述是长裙。这种冲突会导致生成的结果很差。

这点细细想来很有意思。假设人工换装,换成“长裙”的话,上衣和裤子都需要被换掉。$\downarrow m(S_0)$将上衣和裤子都归入了“其他”类,这样和长裙才能对应起来。如果衣服没有这么多款式,比如做纯衬衫的生成,就不存在冲突,也就不需要这步了。
2.2 形状生成
$\tilde S \in [0,1]^{m \times n \times L}$,和$S_0$姿态一样,但各分块符合d中的描述。因为生成的是语义分割映射,所以每个生成的像素点也都是7个标签的softmax编码。

3 纹理渲染$G_{\rm image}$
3.1 合成映射
比以往的GAN多了合成映射层compositional mapping layer。对每个类别训练一个通道,将属于第l类的像素点集记为$P_l$,最终图像$\tilde I$中的第p个像素记为$(\tilde I)_p$,则:
$$(\tilde I)_p = \sum ^L_{l=1}\mathbf l_{p \in P_l} \cdot (\tilde I_l)_p$$
$\tilde I_l$是第l类的通道(即所有的$\tilde I_l$构成合成映射层),$\mathbf l_{(.)}$是示性函数,即
$$
\mathbf l =
\begin{cases}
1, & p \in P_l \\
0, & p \notin P_l
\end{cases}
$$
$(\tilde I)_p$实际上是在像素级别上,以是否属于各类别为权重(0或1)的网络输出加权和。
3.2 图像生成
因为多了一层合并映射,所以tanh是在这层之前的。
4 网络细节和训练
两个阶段分开训练。
设计编码d是50维,其中10维是人的参数:性别、长/短发、戴/不戴帽子、带/不带眼镜一共4维。皮肤RGBY值4维,高、宽2维。剩下40维是句子的嵌入编码。输出128*128的图像。
$S_0$经过双三次下采样得到8*8的$\downarrow m(S_0)$。头发和脸区域在生成图像中直接使用原图替换。
数据集是DeepFashion,人工打上标题描述着装。语义分割的数据是用ATR数据集训练的VGG先分割一遍再人工修正的。
5 结果
常规结果

结果矩阵。行:相同的输入图片;列:相同的文字描述

插值渐变

项目主页,论文、代码和数据集都在里边了。
体会
SSGAN是先从均匀分布的噪声生成法线图像,然后将法线图像作为条件,再从均匀分布的噪声生成照片级图像。
FashionGAN是先进行语义分割作为条件,再生成符合图像和文本描述的形状蒙版。
可以看到,自LAPGAN以来,将CGAN嵌入到复杂过程中似乎是一个趋势。就看怎么处理数据能够喂入GAN生成结果了。
CGAN多模态的威力真的很强大,这几篇文献给出了很好的例子。场景过程、信息编码以及结果处理,是将CGAN应用到各领域的三大关键部分。