原文
DesIGN: Design Inspiration from Generative Networks
GAN强大的生成能力让它在设计领域备受重视。这是一篇Yann LeCun大佬参与的人工智能+设计方向的文章,和之前分析过的、也是本文主要参考文献之一的CAN相比,不仅应用领域直指最实用的服饰,而且干脆给网络起名Design,可以说要在设计领域当仁不让了。
以往的创新性绘画生成使用遗传算法和预定义的适应度函数,并且需要样本图片。
GAN生成是在模仿,缺乏创造性
CAN鼓励生成和已有风格不同的结果,适合抽象绘画,但对写实主义、标准化产品的创意生成没有评判
1 概述
- 探索使用不同的GAN模型生成服饰
- 构造新型损失函数以鼓励生成结果的创新性
- 分解了形状和纹理的生成过程(遵循了服饰设计中的基本要素)
- 难点:生成结果的评价和优选:结合自动评测与人工评测
- 比CAN的效果要好,创新性和相似性得分都是目前最高
2 创新点
- 首次提出了时装图像的创意损失函数
- 考虑到了纹理和形状
- 从已有案例的衍生中学习
- 搭建新应用
- 首次提出了结果更好、更通用的多类别交叉熵准则用于学习,以从已有的形状和纹理中衍生
- 构造基于熵的时装纹理和形状自动评测准则,结合人工调研,给出了一些有用的结论
- 提出了让风格GAN以非确定方式运行的具体解决方案,使用创意损失进行训练,得到创新而有效的模型
4000张512*512的训练集,超过60%的生成图片被设计师认为是人工设计、并且具有原创性
3 损失函数
3.1 判别器
使用形状标签$\hat t$、纹理标签$\hat s$,让判别器学习出形状分类器$D_s$和纹理分类器$D_t$。判别器可以包含两种分类器中的一个或全部。用记号$D_{b,k}$代表分类器$b$及其相应的分类$k\in \{1,…,K\}$,则损失可以表示为:
$$
\mathcal {L}_D = \lambda_{D_r}\mathcal L_{D {\rm real/fake}} + \lambda_{D_b}\mathcal L_{D {\rm classif}}
$$
其中,分类损失为
$$
\mathcal L_{D {\rm classif}} = - \sum _{x_i \in \mathcal D} \log ({\rm softmax} (D_{b,\hat c_i} (x_i)))
$$
3.2 生成器
生成器的损失为
$$
\mathcal L_G = \lambda _{G_r} \mathcal L_{G {\rm real/fake}} + \lambda_{G_e} \mathcal L_{G {\rm creativity}}
$$
其中,创意损失$\mathcal L_{G \rm {creativity}}$借鉴CAN中的创意损失。CAN中的创意损失使用本文定义的符号可以表示为($\sigma$为sigmoid函数)
$$
\mathcal L_{\rm CAN} = - \sum _{x_i \in \mathcal D} \sum ^K_{k=1} \frac{1}{K} \log (\sigma (D_{b,k}(x_i))) + \frac{K-1}{K} \log (1-\sigma (D_{b,k}(x_i)))
$$
衡量了sigmoid函数输出和均匀分布的交叉熵,其意义是使生成的结果在判别器看来不属于已经有的任何一种类型。
CAN的创意损失存在的问题是,由于使用的是sigmoid二分类,用无标签的生成图像训练生成器,二分类的交叉熵在接近0和1的损失都很大,这就会让损失函数对负样本的惩罚很大。虽然最后的结果仍然看起来不像任何一类,但它们的创新性确实被上述问题削弱了,在所有分类上只是趋向于1/K——“不像”得太均匀,也就导致了平庸。
想想看,生成了一个完全不属于某个类别的结果,因为二分类太接近于0,惩罚很大,和接近1是类似的,导致这个结果反而是“不好的”结果。
因此文章使用了softmax多分类,采用多分类交叉熵MCE来衡量全局CAN损失:
$$
\begin{aligned}
\mathcal L_{\rm CAN(H)} & = - \sum _{x_i \in \mathcal D} \frac{1}{K} \log {\rm softmax} (D_b(x_i)) \\
& = - \sum _{x_i \in \mathcal D} \frac{1}{K} \log \left(\frac{e^{D_b,\hat c_i(x_i)}}{\sum ^K_{k=1}e^{D_{b,k}(x_i)}} \right)
\end{aligned}
$$
全局CAN损失实际上是在衡量softmax输出和均匀分布的相对熵,因为均匀分布是常数(这样说来,CAN衡量的是sigmoid和均匀分布的相对熵)。softmax能够综合考虑不像所有类别的程度,不会造成“不像均匀化”的结果。
插一个无聊的小知识:最小化KL散度的方法叫Minxent方法,或Principle of Minimum Cross-Entropy,缩写也是MCE,和多分类交叉熵Multi-class Cross-Entropy的缩写MCE一样,好巧哦=_=
4 网络架构
文章测试了三种网络架构,分别是修改了输出图像尺寸的DCGAN(CAN就是用的DCGAN架构),不带文本输入的StackGAN,和文章提出的StyleGAN。
4.1 无文本StackGAN
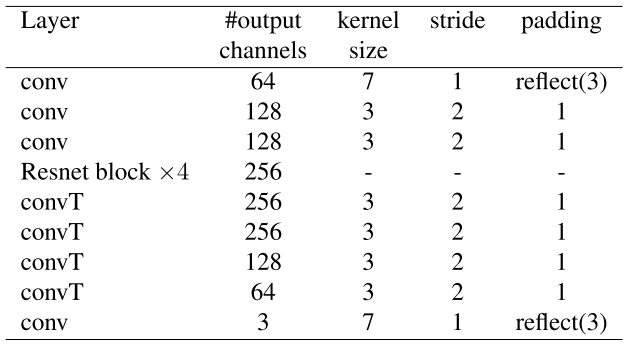
StackGAN是一种分步生成的架构,先用一个GAN生成低分辨率的小图片,再输入到另一个GAN生成高分辨率的大图片,最初用于从文本生成图像。无文本StackGAN去掉了StackGAN的文本输入,而用DCGAN生成一个64*64的低分辨率的图像作为输入。然后受到pix2pix启发,加入4个残差块生成高分辨率图像。原StackGAN中,上采样是通过最近邻实现,本文的StackGAN则是用反卷积上采样,得到256*256的清晰图像。
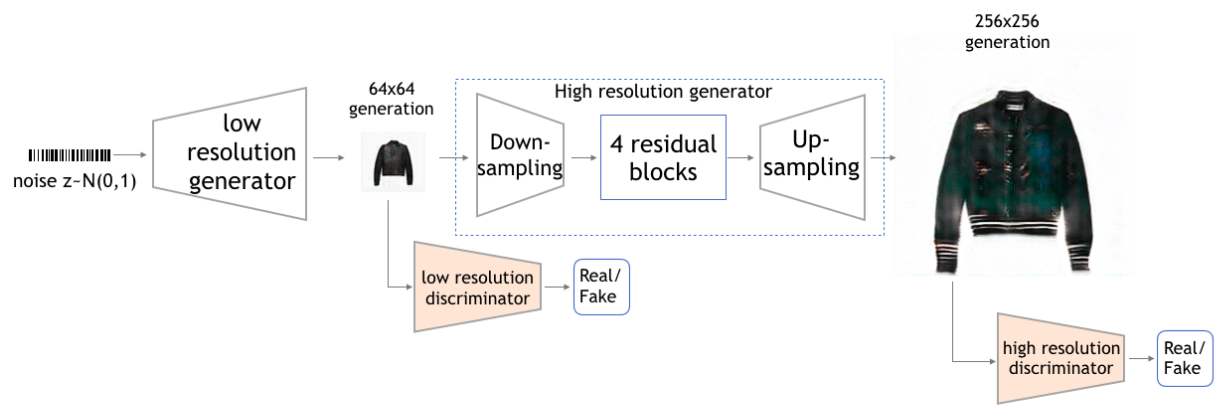
生成高分辨率图像的网络详细结构如下,除了最后一层,其他每层卷积/反卷积都跟着BN和ReLU;最后一层没有BN,跟的是tanh。
4.2 StyleGAN
StyleGAN以二值形状蒙版作为需求的形状,以随机噪声输入生成纹理。这也符合服饰设计流程——形状和图案是分开的。蒙版的计算采用的是Random Walker随机游走算法。采用了ECCV’16文章Generative Image Modeling using Style and Structure Adversarial Networks的结构
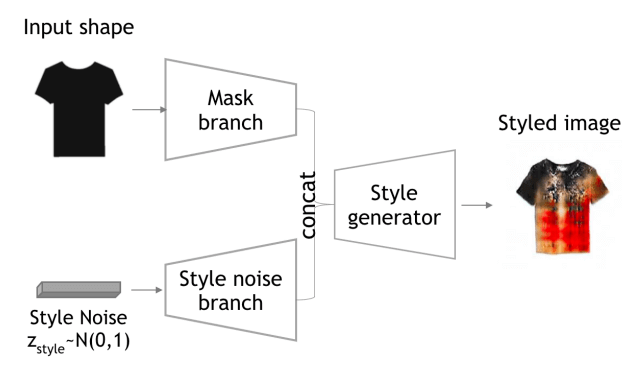
网络细节如下,除了最后一层,其他每层跟BN,卷积层跟Leaky ReLU,反卷积层跟ReLU,最后一层跟tanh。对蒙版卷积下采样,对噪声反卷积上采样,然后将两个结果拼接起来再进行一波卷积和反卷积。

以往的图像到图像的模型,比如pix2pix,CycleGAN,都是建立了输入图像和单幅响应图像之间的确定性映射。而拥有多模态输入的生成器很难训练,因为有时某些输入会被忽略。为了在相同形状下对不同纹理进行采样,加入一个L1损失来避免确定性映射:
$$
\mathcal L_{rec} = \sum _i \sum _{p \in \mathcal P} |G(m_{i,p},z_i=0)-m_{i,p}|
$$
其中,$m_{i,p}$是输入图像$x_i$在像素p处的蒙版,P为蒙版$m_i$的像素集。万一随机噪声为0,可以重构输入蒙版,保证噪声上采样分支上的权重的影响。
5 评价方法
5.1 自动评价
自动评价由3部分构成,Inception score,AM score和kNN均值距离。
Inception score
$$
I_{score}(\{x\}^N_1) = exp(\mathbb E [KL(C(x)||\mathbb E[C(x)])])
$$
衡量生成结果的多样性和质量。形状和纹理分开评测,本文使用的是Resnet-18。
AM score
$$
AM_{score}(\{x\}^N_1) = \mathbb E[KL(\bar C^{train}||C(x))-KL(C^{train}||\mathbb E[\bar C(x)])]
$$
其中$\bar C^{train} = \mathbb E[C(\bar x)]$
AM score将训练样本的分布考虑了进来,改进评价
kNN均值距离
用于衡量结果是在创新而不是在重复。计算每个样本和由它检索到的kNN的平均距离
至于由样本检索kNN的方法,看得不是非常明白,应该是计算Restnet-18去掉最后一层fc得到512维特征之间的欧几里得距离进行度量,得到距离样本最近的10个近邻。
不过这一项的得分高,可能很创新,也可能很失败,比如太创新了反而不够真实。
5.2 手动评价
使用AMT,总体1-5评分,形状和纹理的新颖性和复杂性1-5评分,以及判断是人还是机器生成的。
自动评价中,采用了CAN和CAN(H)损失的DCGAN各项得分在衣服生成上得分较高;DCGAN架构+CAN(H)损失在人工评价中的表现最好。(所以StackGAN和StyleGAN然并卵啊……)
6 数据集
Ready To Wear,4157张图像,7类衣服形状,7类纹理
Attribute discovery,5783张图像,7类手提包形状,7类纹理
7 结果展示
DCGAN生成的结果

kNN检索示例

更多生成结果


体会
虽然文章的标题和贡献写的看起来很厉害,并且指出了CAN应用领域上的局限,但是仔细考虑一下本文的结果,衣服和箱包上的图案也是抽象画啊!只不过CAN是方形画布,DesIGN是衣服/包形画布而已。
StyleGAN中的蒙版生成形状在文中表述的不够,看完文章之后有种蒙版就是CGAN的输入条件的感觉,因为似乎形状生成这一分支能够生成创新性服装版型的可能性不大,文中的服装版型都是类似的。
一句话概括,文章改进二分类的CAN损失,提出了多分类的CAN(H)损失;提出了效果一般的改进的StackGAN和StyleGAN架构;提出了评价方法并做了大量评测,最终测出来还是DCGAN+CAN(H)最好。
我认为和kNN的结合才是最容易落实到产业的,根据用户需求生成一张图片之后,第一反馈给产品的设计师改进或研发新产品,第二检索商品库中类似的商品推荐给用户,比传统的以图搜图或者根据用户行为的统计数据推送要精准得多。